从2021 MAD Landscape谈下未来数据领域10大趋势

之前经常会看FirstMark发布Machine Learning, AI and Data (MAD) Landscape,最近正好看到一篇他们在21年底时在Data Driven NYC做的演讲,演讲中总结了未来MAD领域的10大趋势,分享给大家:
- 未来每个公司都将是数据公司
- 数据仓库和数据湖将大行其道
- 趋于融合:数据集中VS数据网格
- 数据赛道正被风投VC疯狂追捧
- DataOps变得愈发成熟和普及
- 实时数据正推动数据赛道变革
- 反向ETL正在成为主流应用需求
- 基于AI进行自动合成内容的兴起
- 数据赛道从MLOps到ModelOps
- 国内将涌现大批AI Stack公司
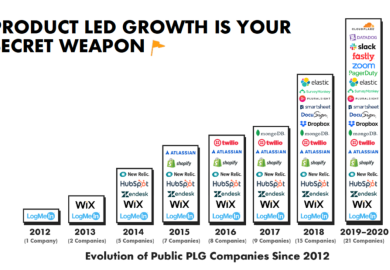
MAD Landscape的由来
在介绍MAD领域10大趋势之前,先给大家介绍下MAD Landscape是什么。
MAD Landscape是由First Mark创造发布的。First Mark是一家专注投资各种早期创业公司的VC,比如像Pinterest,Shopify,Airbnb,Discord,Cockroach Labs,Dataiku…..都是他们佳作,他们对数据、机器学习和人工智能领域的初创公司尤为感兴趣。
早在2012年,当所有人都在谈论大数据,以及Hadoop将如何征服世界,他们率先提出了Big Data Landscape,但是随着大数据和人工智能领域被推上风口浪尖时,他们又提出融合机器学习、人工智能和数据的MAD(首字母缩写)Landscape,之后每年将最有潜力的新兴创业公司更新其中并延续至今。
在第一版Landscape发布的时候,大家都觉得未来这个领域会趋于集中整合,没想到10年之后,随着移动互联网的普及,MAD非但没有一家独大反而是更加细分,充分说明数据正在驱动整个世界运行,这个领域也正变得越来越体系化和专业化,一起看下该领域最新的10大趋势。
未来每个公司都将是数据公司
首先看第一大趋势,面对越来越残酷的市场竞争,未来每家公司不仅要成为互联网公司,还要成为数据公司,这是企业数字化转型必然趋势,过去人们关注大数据处理,现在开始关注AI,在过去几年间,越来越多的公司开始从依赖Excel进行数据分析转变为依靠大数据、人工智能驱动决策,这意味企业将越来越依赖来自客户、供应链、市场…的数据用于辅助企业实时决策,为公司创收。
数据仓库和数据湖将大行其道
第二大趋势是关于DataWarehouse 和 LakeHouses的兴起和争辩。
以前,大家对于存储和处理大数据,觉得自建Hadoop就是终极解决方案,但随着云DataWarehouse和LakeHouses的兴起,让越来越多的普通用户也可以低成本、0门槛享受大数据平台的便利,典型代表就是Snowflakes和Databricks。现在每个公司都可以随时随地在Cloud上创建他们的Snowflake实例,让自己更容易转变为数据驱动型公司,他们还可以基于Snowflake上提供的ML和AI能力做辅助分析,让更多的人释放出来,做更有价值的事情。
当前围绕云数据仓库已经形成了一个完整生态,很多人将其称为现代Data Stack,这也标志着生态中将出现很多新一代初创公司,围绕这类集中式的数据平台做上层应用,但这就是全部的未来吗?
趋于融合:数据集中VS数据网格
于是就出现了第三大趋势,数据集中 VS 数据网格之争,我之前写过一篇《兼谈数据中台和DataFabric》详解两者的差异。
像Snowflakes,Databricks,他们已经提供了一个以他们为中心的完整数据生态体系。无论是数据采集、集成、清洗、加工、分析、治理、可观测性,都是应有尽有。这类中心化数据平台的用户基本上是两极分化,要么是无法自建技术团队的传统大型公司,要么是一些规模很小的初创企业,大型科技公司则非常少。
于此同时我们看到有许多更小、更年轻、更灵活的初创公司围绕更加垂直的领域构建其解决方案,每个方案专注完美解决一个问题,呈现去中心化的趋势。最明显的就是越来越多垂直领域中的佼佼者开始走入人们的视线,并且大家都在试图用数据网格的模式将这些解决方案联系在一起,形成新的数据平台,无论是初创公司还是开源项目。现在头部提供中心化数据平台的公司依靠雄厚的财力正在寻找此类的收购机会,但有趣的是愿意被收购的初创企业并不多。
数据赛道正被风投VC疯狂追捧
第四大趋势是MAD领域正被风投VC疯狂追捧。
当前数据领域的产品可谓百花齐放,过去几年数据赛道的融资环境十分疯狂,仅在2021年上半年,就有42家AI独角兽诞生,而2020年全年只有11家。并且,2021年上半年在AI和ML方面的融资金额就超过360亿美元,而2020年全年的总融资为380亿美元。2021年几乎是2020年的2倍,像头部的Data Bricks直接拿到了16亿美元的巨额融资,估值高达380亿美元。而Celonis则融了10亿美元,估值高达110亿美元…
在资本收购方面更是大手笔不断,微软以200亿美元收购了语音和文本识别领域的Nuance,松下以85亿美元收购了供应链物流领域的Blue Yonder,Segment以23亿美元收购Twilio…
由此可见其,当前数据赛道的公司规模和融资金额都呈现出爆炸式增长,尤其是在Infra方面,全球企业数字化转型已是箭在弦上。
DataOps变得愈发成熟和普及
第五大趋势是随着MAD图谱中的产品越发成熟,整个生态已经走出蛮荒阶段,DataOps正在将更成熟的 DevOps和软件工程实践中的最佳实践带入数据世界。
在过去几年围绕关键领域的单一解决方案和工具正在呈现爆炸式增长,像数据可观测性,很多人将其定义为Data Stack领域的Datadog,通过对数据全生命周期的监控和告警,帮助用户更快感知和发现数据在使用中出现的各种问题,比如:
- 数据血缘(data lineage),数据血缘记录每条数据的执行过程和转换历史。对监控、审计、识别和修复数据管道中可能发生的任何问题都非常有用
- 数据可观测性,用于监控流动中的数据质量,例如当数据库表中的列不能为空,或者以自动化方式,利用机器学习来监控和验证数据合规性
在数据访问和治理方面,除了像Elation或Collibra这类大型公司之外,也涌现出很多挑战者进入这个领域,为用户提供下一代DataOps相关产品,根据Gartner统计在2022年DataOps将被广泛数据工程师、产品经理、数据管理员运用在组织协同和交流之中,因此DataOps在流程、文化以及工具方面也将变得越来越成熟。
实时数据正推动数据赛道变革
第六大趋势是实时数据正推动数据赛道变革。
在过去很长一段时间,大家都认为面对海量数据,批处理可能是唯一的方式,但是在过去几年,实时数据技术正在悄无声息的影响整个数据领域,比如Confluent(Kafka商业化公司)专注实时数据传输垂直领域,创业7年后在2021年成功以80亿美元的估值登陆纳斯达克,最高市值一度超过230亿美元,这充分证明了市场对实时数据基础软件提供商的强劲需求。
同样的事情,在市场的不同角落,也在不断发生,比如专注实时分析领域开源项目ClickHouse,它始于Yandex,在2021年作为商业化公司分拆出来后,也拿到了3亿美元的融资,估值超过20亿美元。
当然MAD图谱中的其它领域也在适配实时数据,特别是围绕实时数据管道有很多新的新兴企业诞生,像Meroxa或Estuary这样的公司,他们正在试图统一批处理和流处理。我们正在做的开源产品Know Streaming(https://github.com/didi/LogiKM)也在解决这个领域实时数据传输可见、可管、可控方面的问题。
反向ETL正在成为主流业务需求
第七个趋势是反向ETL正在变为主流业务需求。
众所周知数据仓库已经出现了好几年,随着Snowflake在IPO市场上独占鳌头,得到众多小公司和大企业的青睐,大家纷纷把自己的数据通过ETL的方式集成到Snowflake中进行集中式分析处理,巧合的是市场中同时涌现了大量从数据仓库中提取特定数据的需求(反向ETL)。
以前,数据仓库被视为集中数据的地方,无论是用户数据还是其他相关数据,都来自上游业务系统、Salesforce、Zendesk、Gainsight等。数据团队过去会在数据仓库中对数据进行统一分析,并将结果传递给相关运营团队使用。而反向ETL则是将在数据仓库中处理后的数据回传给生成数据的上游系统,这意味着现在Salesforce可以保存来自Zendesk的客户票务数据、来自Stripe的账单信息、来自Gainsight的客户交互数据等等。然后,业务人员可以在Salesforce中统一处理这些数据,对客户全生命周期活动进行分析,这意味着更广泛的共享数据视图,让组织中的每个人都可以按需使用自己关注的数据。
在去年有很多这样的公司拿了大量的融资,这是个值得重点关注的领域。
基于AI进行自动合成内容的兴起
第八个趋势是基于AI进行自动合成内容的兴起。
过去无论是视频、文本还是介于两者之间的任何内容,都需要人工亲自编辑,但是在最近几年利用AI自动合成这些内容已经开始有了真正的应用。去年有几个非常典型的例子:
- 有患者在与癌症作斗争后失去了声音,可以通过AI学习他之前的声音进行模拟,帮助其通过合成声音进行说话。Synthesia最近与乐事和梅西合作,可以为用户定制内容,这些内容可以按名称、语言和一系列的选项进行定制。
- GitHub Copilot通过GPT3在GitHub下载了很多代码,然后使用NLP进行大规模生成代码,虽然该项目还在非常早期阶段,但是过去几年他们已经发布了一堆商业应用。
在创业方面,合成媒体的发展势头良好,尤其是在语音和视频领域,想想头条即可,我们每天看到的新闻90%以上都是AI编辑产生的,之前大家可能觉得AI离我们很远,但其实AI就在我们身边。
数据赛道从MLOps到ModelOps
第九大趋势是MLOps趋于成熟与ModelOps开始出现早期应用。
MLOps已经被Gartner提了很多年,无论是标准化流程、基础设施、模型部署、服务以及培训,还是在测试和部署方面,MLOps都将是DevOps应用于机器学习的最佳实践。
除了早期以技术为中心的大型应用之外,围绕它的工具也开始成熟,而这次提到的ModelOps相当于MLOps的超集。ModelOps不仅关注机器学习模型,而且将所有AI模型可操作化。它将所有模型集中起来,并围绕这些模型形成标准化应用流程。在这种情况下,这有助于为模型进行全面的治理和审计。不仅为数据科学家、机器学习工程师带来了更好的可解释性,而且让业务人员更好的理解可解释性,比如为什么某些模型会产生当前的结果,是什么因数会导致结果发生变化…说直白点就是让AI白盒化、可预测和解释,这个领域最近非常火。
在ModelOps和MLOps中,商业化仍处于早期阶段,但是在围绕机器学习和更广泛的AI模型训练过程中出现了很多单点解决方案,无论是在模型监控、模型部署还是特征存储,未来一定会出现更多的扩展和应用,可以关注下Ascend和Mona这两家公司。
国内将涌现大批AI Stack公司
第十大趋势是国内开始涌现大批AI Stack公司。
在人工智能领域,中美之间正在进行激烈的较量,我们作为全球最大的数据生产国,拥有巨大的市场优势,这将催生我们作为全球人工智能强国不断成熟。在2019、2020年,我们看到像TikTok这类国内消费科技首次大规模风袭欧美世界,众所周知,TikTok可以说是有史以来最好的AI推荐算法之一,这也是我们为何一单刷起来根本停不下来的原因。
回想过去几年,国内的基础设施还很薄弱,但随着政府的推动以及包括2018年华为事件在内的一系列升级,让我们意识到,一定要解决卡脖子关键技术,因此国内开始从0建立完全自主可控的基础设施生态,软硬件国产化、基础软件信创开始逐步落地成型,政府的长期支持和企业的商业化探索已经开始得到回报,国内MAD领域开始涌现大量商业化和开源工具。我们现在的开源产品Know Streaming(https://github.com/didi/LogiKM)也有幸荣登21年科创中国开源创新榜单,也算为国内基础设施生态做了一点自己的贡献。
Recent Posts